Research
Improving Performance of Graph Processing and Mining
As graph-structured data is becoming prevalent, there is a growing demand for HPC systems for learning and extracting information from graphs. The large size of the graphs imposes a new challenge for graph processing algorithms to benefit from GPUs with limited memory. In this project, we aim to design new data placement and movement strategies and new algorithms for efficient training of graph neural networks on large-scale graphs.

Understanding and Mitigating Error Propagation in HPC Applications
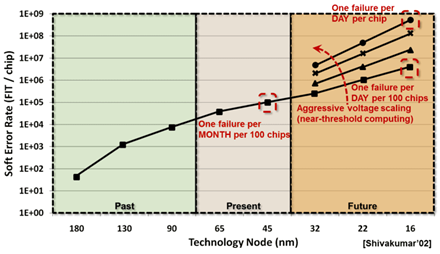
Hardware transient faults (e.g. soft errors) are increasingly prevalent nowadays as the size of transistors keep shrinking. These hardware faults can be read by software applications executing in the system, seriously compromising the correctness of the computation. The problem is exaggerated in HPC applications due to their long-running nature and becomes one of Top 10 challenges in HPC system design. Traditional approaches in HPC resiliency incur huge overheads in performance and energy consumption, hence are hard to scale to the next-generation HPC systems. Our goal in this project is to improve HPC resilience against hardware faults by designing efficient and effective fault-tolerance techniques at HPC software level, mitigating error impact at low cost in the next generation HPC systems.